In this article we are going to look at how HSRP behaves in two scenarios which are based on what happened to a colleague of mine in the live network. Basic knowledge of how HSRP functions is needed in order to understand what happens here.
The topology is fairly simple:
- The routers running HSRP are
R1andR2for both sides of the network. - The virtual IP is set as a gateway for
AandBso there is complete reachability between them. SW1andSW2have the role of a switch and are used in order to simulate interface outages.AandBare simulating end-hosts not routers!
The project and initial configs can be found here: hsrp-preempt.zip
The Setup
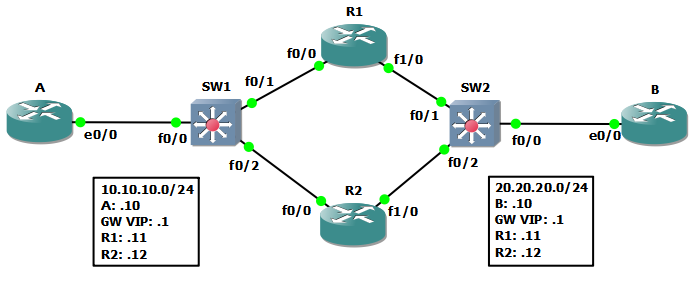
The configuration for HSRP on R1 and R2 is as follows:
! ###### R1 ######
interface FastEthernet0/0
ip address 10.10.10.11 255.255.255.0
standby 10 ip 10.10.10.1
standby 10 priority 105
standby 10 preempt delay minimum 60
standby 10 track FastEthernet1/0
!
interface FastEthernet1/0
ip address 20.20.20.11 255.255.255.0
standby 20 ip 20.20.20.1
standby 20 priority 105
standby 20 preempt delay minimum 60
! ###### R2 ######
interface FastEthernet0/0
ip address 10.10.10.12 255.255.255.0
standby 10 ip 10.10.10.1
standby 10 preempt delay minimum 60
standby 10 track FastEthernet1/0
!
interface FastEthernet1/0
ip address 20.20.20.12 255.255.255.0
standby 20 ip 20.20.20.1
standby 20 preempt delay minimum 60
The rest of the configuration can be found in the attached archive.
A few things can be noticed from the output above:
- The active router is
R1because of its higher configured priority, withR2as standby. - Both are configured to preempt, but with a delay of
60seconds. - We are tracking the
20.20.20.xinterfaces from the10.10.10.xinterfaces, but not vice-versa.
After all the routers/switches have been started, the state should be as follows:
R1#show standby brief
P indicates configured to preempt.
|
Interface Grp Prio P State Active Standby Virtual IP
Fa0/0 10 105 P Active local 10.10.10.12 10.10.10.1
Fa1/0 20 105 P Active local 20.20.20.12 20.20.20.1
R2#show standby brief
P indicates configured to preempt.
|
Interface Grp Prio P State Active Standby Virtual IP
Fa0/0 10 100 P Standby 10.10.10.11 local 10.10.10.1
Fa1/0 20 100 P Standby 20.20.20.11 local 20.20.20.1
As expected, R1 is active on both sides of the network and traffic will flow through it. Looking on SW1, we can see that the HSRP MAC has been learned on the proper port:
0000.0c07.ac0a Dynamic 1 FastEthernet0/1
Scenario Number 1
Let's say that the cable between R1 and SW2 is faulty and the link goes down. We will simulate this by shutting down the interface on SW2.
But before doing that start a ping with a large repeat count from B to A.
As soon as we shutdown the interface, the ping will stop working. That is not good, what's our redundancy doing? Looking at R2, after 10s (the default dead timer) it detects that R1 is unreachable (group 20) and switches from Standby to Active:
R2
00:00:59.147: %HSRP-5-STATECHANGE: FastEthernet1/0 Grp 20 state Standby -> Active
Interface Grp Prio P State Active Standby Virtual IP
Fa0/0 10 100 P Standby 10.10.10.11 local 10.10.10.1
Fa1/0 20 100 P Active local unknown 20.20.20.1
This was expected, apart from the fact that for group 10 (the left side) R1 is still the Active router. That explains why our ping is not working anymore. The replies are going to R1 whose interface to 20.20.20.x is down.
But why didn't group 10 switch to R2 as well, given that we are tracking the interfaces on the right side (group 20) and we have preempt enabled?
The answer is preempt delay. On R1, the HSRP process will detect that the link is down on Fa1/0 and will decrease the priority on the Fa0/0 interface (tracking will decrease it by 10) resulting in a priority of 95 for R1. So now R2 has a higher priority (100) and it is configured to preempt, but the 60s delay configured forces it to wait before taking the active role.
And this is what happens:
R1
00:02:00.751: %HSRP-5-STATECHANGE: FastEthernet0/0 Grp 10 state Active -> Speak
00:02:10.747: %HSRP-5-STATECHANGE: FastEthernet0/0 Grp 10 state Speak -> Standby
R2
00:02:00.411: %HSRP-5-STATECHANGE: FastEthernet0/0 Grp 10 state Standby -> Active
At 00:00:59, R2 detected that for group 20 the Active router (R1) is no longer reachable and switched to Active. At that point, R1 decreased its priority due to interface tracking and the preempt timer was started. At 00:02:00, 60 seconds later, R2 takes over the Active role for group 10 and R1 switches to Standby mode.
Also, this behavior can be observed by following the mac-address-table for SW1 and SW2 while this change is in progress to see how the HSRP MAC moves between interfaces at each step.
After all of this happens, the ping starts to work again as expected.
Why did this happen?
First of all, even if both sides have preempt enabled and 60s timers, only the left side (group 10) will preempt when our link goes down. This happens because preempt works only when the priorities change. This is very important to note, because in group 20 nothing will ever modify the priorities (there's is no tracking enabled).
When the group 20 link goes down, the trigger for the change of role will be the dead timer (10s by default). At the same time, in group 10 the interface tracking will decrease R1's priority to 95 and then R2 becomes able to take the active role because of preemption. But it does not do so instantly, as it has the 60s preempt delay configured.
As such, during this time between the two changes we will have asymmetric routing: packets from B to A will go through R2 but the replies will go through R1, hitting a dead end.
What can we do about it?
If we want to minimize the impact such an event would have on the passing traffic, we could lower the preempt delay. In essence, this is what dictates the length of the period of black-hole routing. This delay has its use in protecting the network from flapping interfaces and in the case that dynamic routing protocols are used, it helps in waiting for them to converge before changing the path the traffic takes.
Scenario Number 2
Let's try a different scenario now, starting from our initial stable configuration. What happens when the link between SW1 and R1 goes down?
Start the ping from B to A before shutting down the Fa0/1 interface on SW1.
When the link goes down, R2 takes over the Active role for group 10 after the dead timer expires:
00:35:38.007: %HSRP-5-STATECHANGE: FastEthernet0/0 Grp 10 state Standby -> Active
Our ping now looks like this:
B#ping 10.10.10.10 repeat 1000000000 timeout 4
Type escape sequence to abort.
Sending 1000000000, 100-byte ICMP Echos to 10.10.10.10, timeout is 4 seconds:
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
!!!!!!U.U.U.U.U.U.U.U.U.U.U.U.U.U.U.U.U.U.U.U
Does anything else happen after this? Not really. Sadly, we are suffering again from asymmetric routing.
Because nothing changed in group 20, when B is sending the ping to A, the packets go to R1. But R1 now has no route towards 10.10.10.x because the interface towards it is down. So it drops the packet and sends a network unreachable packet back to B.
Why isn't R2 becoming Active for group 20 as well? As far as it is concerned, group 20 is working properly. Both routers can reach each other on their group 20 interfaces so everything is fine. In this configuration, it will not switch unless R1 goes down (or its Fa1/0 interface).
What can we do about it?
If you look at the initial configuration, you will notice that it is not symmetric. We are tracking Fa1/0 from group 10, but not the other way around. So the solution in this case would be to add tracking to group 20 as well (track interface Fa0/0). This would ensure that the same thing happens as in Case 1.
What happens when the link comes back up?
As soon as the link is working again, traffic will instantly start to flow again. How come this is happening, when we have a 60s preempt delay? (R1 will have to wait before taking the Active role back from R2 for group 10).
This works even if R1 is Active in group 20 and R2 in group 10 because now both links are up and working and packets from B->A will go through R1 and the replies from A->B will go through R2. This asymmetric routing will keep working until R1 preempts for group 10 and we are back to our initial, symmetric and working scenario.
During this asymmetric period, we can check the MAC tables on the switches:
SW1
0000.0c07.ac0a Dynamic 1 FastEthernet0/2
SW2
0000.0c07.ac14 Dynamic 1 FastEthernet0/1
The conclusion
Be careful when configuring interface tracking, if both sides in the routed path are running HSRP then they need to track each other.
In an access-layer scenario, you generally don't have this problem as only the server-facing interfaces run HSRP and the upstream interfaces usually have an IGP doing all the hard work. But it can happen that servers are on one side and firewalls on the other, so make sure you catch all the failure scenarios at design time!
And remember, preemption doesn't work if priorities don't change!