It all started a while ago with a log message found on the hub of a large DMVPN/IPSEC deployment over mobile Internet connections. Given the increasing number of deployments that use the Internet as a cheaper, faster WAN for either primary or backup, I thought it would be useful to document the problems and the two main solutions.
*Mar 25 23:44:27.668: %NHRP-3-PAKERROR: Received Error Indication from 172.16.0.1, code: loop detected(3), (trigger src: 172.16.0.2 (nbma: 10.0.2.2) dst: 172.16.0.254), offset: 84, data: 00 01 08 00 00 00 00 00 00 FD 00 B9 09 E5 00 34
The message above (taken from my lab environment) is full of interesting (and rather confusing) information... what's this about a NHRP error and a loop?
First, the investigation
To start with, let's talk about the environment where this was all discovered: a DMVPN/IPSEC hub'n'spoke cloud, with branches connecting over mobile Internet and the head-end via fibre based connectivity.
Over the course of the deployment (and the initial testing) everything seemed to work fine - it wasn't until later on (when branches started to number in the hundreds) that the log messages started to appear.
After doing a bit of digging online and figuring out what the IPs referred to in the message we understood that, for some reason, NHRP was complaining that two different branches had the same NBMA IP. It was quite odd indeed, as all the branches had unique IPs on their Tunnel interfaces and were getting unique IPs from the mobile provider on their Cellular interfaces.
Until it hit me. It's mobile Internet. It most likely goes through a Carrier Grade NAT device before exiting towards the Internet (extra hint: the Cellular interface had an unroutable 100.64.0.0/10 range IP). And CGN, among other beautiful application specific kludges, usually does PAT (Port Address Translation or NAT overload).
This means that multiple mobile devices behind the CGN could be hashed on the same public IP for NAT. While IPSEC can deal with NAT, one hard requirement of NHRP is that the peer IPs have to be unique.
As Cisco's recommendation is to configure IPSEC in transport mode in a DMVPN scenario, the CGNAT device was translating the source IP of the branch that was used by both IPSEC and NHRP, sometimes using the same public (Internet routable) IP from its pool as for other branches.
When that happened, all the branches that had the same public IP as an existing DMVPN session caused the log message above to appear and failed to establish the tunnel (NHRP said something was fishy, so tunnel stayed down).
Then, the lab setup
To recreate and confirm the hypothesis, I started a bunch of IOSv nodes in VIRL and quickly configured the topology you see below. BR-1 and BR-2 are branch routers, NAT is the CGN wannabe (doing NAT overload on the 50.0.0.3 interface) and HE is the DMVPN/IPSEC head-end router, terminating tunnels from the branches. The link between NAT and HE is pretty much an oversimplified Internet.
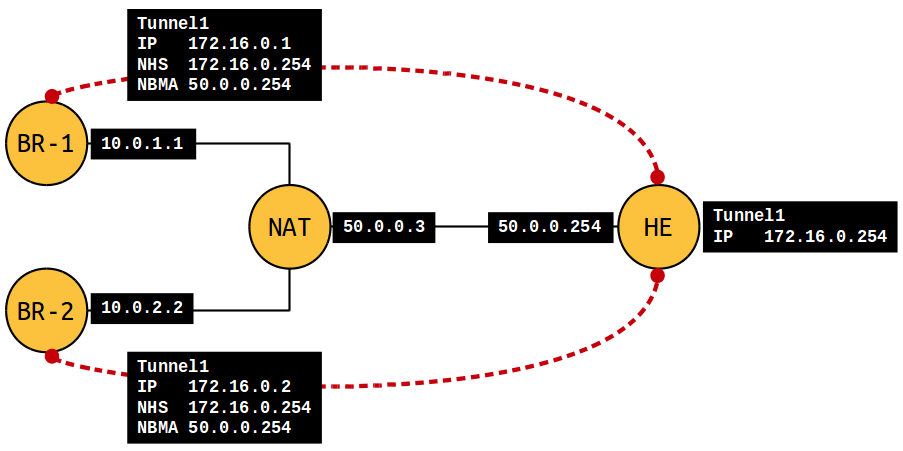
So first of all, let's look at a show dmvpn command output without NAT. This is the cleanest form where tunnels are unchanged end-to-end: pretty cool, both tunnels are up.
# Ent Peer NBMA Addr Peer Tunnel Add State UpDn Tm Attrb
----- --------------- --------------- ----- -------- -----
1 10.0.1.1 172.16.0.1 UP 00:05:30 D
1 10.0.2.2 172.16.0.2 UP 00:04:40 D
Now, let's turn on PAT. This hides both BR-1 and BR-2 behind 50.0.0.3. One branch establishes its tunnel, in this case BR-2 is first.
# Ent Peer NBMA Addr Peer Tunnel Add State UpDn Tm Attrb
----- --------------- --------------- ----- -------- -----
1 50.0.0.3 172.16.0.2 UP 00:03:13 DN
Then BR-1 wants to get its tunnel up as well, but tough luck.
# Ent Peer NBMA Addr Peer Tunnel Add State UpDn Tm Attrb
----- --------------- --------------- ----- -------- -----
2 50.0.0.3 172.16.0.1 UP 00:00:17 DN
172.16.0.2 UP 00:04:27 DN
As its source IP gets also NATd to 50.0.0.3, NHRP complains and the tunnel stays down.
*Mar 25 23:44:27.668: %NHRP-3-PAKERROR: Received Error Indication from 172.16.0.1, code: loop detected(3), (trigger src: 172.16.0.2 (nbma: 10.0.2.2) dst: 172.16.0.254), offset: 84, data: 00 01 08 00 00 00 00 00 00 FD 00 B9 09 E5 00 34
The solution, please
Ultimately, the solution was pretty simple. If IPSEC can handle PAT and NHRP can't, then let's hide all this PAT smelly stuff from NHRP: the only way of doing this is to change to IPSEC tunnel mode.
Tunnel mode adds an additional IP header into the mix, while encapsulating the original packet completely. The PAT then only changes this visible outer header (remember the inside is actually encrypted and encapsulated by ESP) and gets discarded at the destination before NHRP gets to look at the packet.
So with tunnel mode, at HE the two processes see the following IPs:
- IPSEC:
SRC: 50.0.0.3DST: 50.0.0.254+ some random UDP ports from NAT-T(raversal) - NHRP:
SRC: 10.0.1.1DST: 50.0.0.254forBR-1 - NHRP:
SRC: 10.0.2.2DST: 50.0.0.254forBR-2
Which means that both tunnels have unique NBMA IPs as far as NHRP can tell and both tunnels can go up:
# Ent Peer NBMA Addr Peer Tunnel Add State UpDn Tm Attrb
----- --------------- --------------- ----- -------- -----
1 10.0.1.1 172.16.0.1 UP 00:01:00 D
1 10.0.2.2 172.16.0.2 UP 00:00:21 D
Bonus: the Attrb column is not showing an N any more, which means NHRP can't tell that there is NAT in the way. IPSEC tunnel mode masks this completely.
The problem is solved, albeit at the expense of a bit more of your MTU. But is it solved completely? Sadly, no.
Oof, it's NAT again, isn't it?
We established that the CGNAT device is very likely to exist and found a solution for it, but in a lot of deployments the HE router will be placed in a DMZ behind a firewall. And guess what that firewall would also be doing?
Yup, NAT. As the DMVPN head-end needs to be routable as a tunnel termination point, it needs a public IP, so unless the DMZ is directly addressed with public IPs, the HE tunnel destination will be a 1:1 static NAT performed on the firewall.
And guess what? When you pair 1:1 static NAT on the head-end with PAT on the branch, IPSEC (at least on IOS) fails somewhere in Phase 2. Looking at debugs, I couldn't figure it out for the life of me, so please get in touch if you know why.
In essence, to keep your sanity, just do not perform any NAT on the head-end side if you still want to use DMVPN.
The TL;DR section
There are two options here, depending on what you've decided to deploy. As you can see above, the DMVPN solution has caveats, while switching to FlexVPN works out of the box even with transport mode.
For DMVPN: use IPSEC tunnel mode and do not perform NAT on the head-end.
For FlexVPN: no restrictions, works with NAT on both sides.
While FlexVPN might seem the most obvious choice here, please note that it is not a drop-in replacement for DMVPN and there are various differences (uses virtual-templates, negotiated IPs, AAA, encryption non-optional etc.) that should be carefully considered.
And, as always, thanks for reading.